Accélérer une suite de tests Django et Pytest sur un poste de développement
Cet article, qui attend sa publication depuis 6 mois, a inspiré la première partie de la conférence Le duo comique accélère une suite Pytest/Django, donnée à la PyconFr 2025.
TL;DR;
Voici un résumé des enseignements que nous avons retirés de cette longue aventure :
- Exécutez votre suite avec
--durations=xxpour afficher les xx tests les plus lents et savoir ce qui est lent (préparation, exécution ou nettoyage). - Désactivez le calcul systématique de la couverture de code, vous n'en avez sûrement pas besoin en local.
- Coupez internet quelques minutes pour détecter d'éventuels tests qui ont besoin d'un appel réseau. Supprimez ces appels réseau à l'aide d'une stratégie de mock adéquate.
- Si possible, réutilisez la base entre deux exécutions avec
--reuse-db; vous pouvez rappeler--create-dben cas de modification de vos modèles. - Évitez d'appeler
set_passwordaprès chaque création d'utilisateur de test. Dans la majorité des cas vous n'en avez pas besoin, vous pouvez créer une session avecforce_login().Pour les rares cas où vous avez besoin d'un utilisateur de test qui dispose effectivement d'un mot de passe, changez de stratégie de hachage de mot de passe pour utiliser le hasher MD5. (UNIQUEMENT en test, attention !) - Pour diviser l'exécution des tests en plusieurs processus, utilisez le paramètre
-nmais évitez-n autoet contentez-vous de 2 à 4 processus (même si vous avez 24 cœurs sur votre machine).
Contexte
Ce n'est pas un secret : chez Hashbang, nous adorons Django. Nos références regorgent de sites basés sur Django, et si vous nous laissez le choix, nous allons vous proposer du Django. Même pour un « tout petit besoin ». Parce que nous savons, pour l'avoir vécu avec chacun·e de nos client·es, que les petits besoins grandissent vite.
Ce que vous ne savez peut-être pas, c'est que nous développons en écrivant des tests unitaires et d'intégration à l'aide de Pytest. Chacun de nos projets Django vit donc avec sa suite de tests pytest, exécutée régulièrement par les développeuses sur leur poste, mais aussi par notre brave plateforme d'intégration continue (la "CI", prononcez si-ail) à chaque fois que nous poussons du code sur nos dépôts git.
La suite de l'article contiendra des astuces probablement applicables à d'autres outils de test, certaines assez propres aux possibilités offertes par Pytest.
Le constat
Une de mes suites de tests sur un projet Django tout à fait classique, en réalité plutôt léger en fonctionnalités, prenait 5 minutes et 22 secondes pour exécuter 369 tests.
Moi j'aime Django, j'aime Pytest, mais je n'aime pas attendre cinq minutes et vingt-deux secondes pour savoir si j'ai cassé l'écran B en ajoutant une fonctionnalité dans l'écran A.
Je ne peux pas travailler en TDD (test driven development) si je dois attendre cinq minutes et vingt-deux secondes à chaque itération dans mon code.
En moyenne, j'ai besoin en moyenne de presque une seconde par test. 0,87 secondes plus précisément. Confusément, je sais que c'est trop long. J'en ai assez de perdre tout ce temps. Je vais me retrousser les manches.

Première étape : l'analyse
Avant de supprimer, pardon, modifier du code au hasard, il faut savoir ce qui est lent.
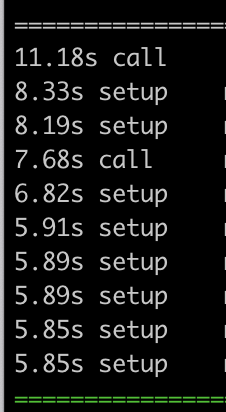
Je relance donc ma suite avec l'option --durations=10 pour avoir la liste des 10 tests les plus lents. Dans ce cas, pytest affiche une information intéressante : est-ce que la lenteur a eu lieu lors de l'exécution du test lui-même (call), dans la préparation de celui-ci (setup) ou dans le nettoyage post-exécution ?
Chez moi, c'est une majorité de lenteur lors des setup, avec deux call seulement qui sont lents. Voyons tout de suite comment j'ai résolu la lenteur des deux call en question… par le plus inouï des hasards.
Lenteur à l'exécution : quand le wifi du TGV aide à poser le diagnostic
Ne m'imaginez pas travailler sur ma suite de tests en trouvant toutes les solutions aussi vite que vous lisez cet article. Il y a eu plusieurs semaines de tâtonnements épisodiques, quelques minutes par ci par là, une recherche sur internet en passant, un petit bout de conversation qui revient sur le sujet.
Bref.
Tout ça pour dire qu'un matin de printemps, avant 8h, j'ai fait tourner ma suite de tests alors que j'étais connectée au wifi du TGV, quelque part dans les champs entre Lyon et Paris. Vous connaissez le wifi du TGV ? Si non, je me contenterai sobrement de vous préciser que, sans aucun doute, ce n'est pas un WGV.
Et quelle ne fut pas ma consternation quand j'ai constaté que les tests étaient alors encore plus lents que d'habitude. En allant relire ces deux tests de plus près, j'ai compris qu'ils effectuaient un vrai appel réseau vers une vraie API extérieure. Depuis presque un an, à chaque exécution. Ce n'est pas du code que j'avais écrit, mais j'en avais quand même la responsabilité et j'étais mortifiée.
Dans l'urgence, j'ai « esquivé » (skip) ces deux tests pour éviter de continuer de surcharger cette API qui n'avait rien demandé.
@pytest.mark.skip(reason="Appel d'une vraie API")
def test_command_creation_bidules():
call_command("initialisation_des_bidules")
assert Bidule.objects.all().count() > 0
Premier enseignement : coupez de temps en temps internet pour exécuter vos suites de test. Si l'un ou l'autre test échoue quand il est privé de réseau, quelque chose ne va pas et il faut sûrement mettre en place une stratégie de mock.
Ici, j'ai mis en place une stratégie de mock toute simple à l'aide du package responses (car le code appelait une API à l'aide de requests). J'ai récupéré et abrégé le contenu réel retourné par l'API, je l'ai sauvegardé dans un fichier et demandé à responses de le retourner à chaque appel de cette API par requests. Voici à quoi ressemble le test maintenant :
@responses.activate
def test_command_creation_bidules():
with open(Path(__file__).parent / "fixtures" / "bidules.json") as handle:
content = json.loads(handle.read())
responses.get(
f"https://liste-de-bidules.fr/api.json",
json=content,
status=200,
)
call_command("initialisation_des_bidules")
assert Bidule.objects.all().count() == 5
Esquiver et corriger ces tests pour éviter les appels réseau m'a fait gagner une vingtaine de secondes. On descend à 5 minutes environ. Mais moi je voudrais gagner plusieurs minutes… au moins.
Une couverture trop lestée
Vous avez peut-être remarqué sur la première capture d'écran que mon terminal m'annonce un taux de couverture (coverage) de 92 %. Ça veut dire que, quand je fais tourner ma suite de tests, 92 % de ma base de code est atteinte (exécutée) à un moment ou un autre.
Cela se fait en ajoutant les options suivantes à notre appel de pytest : --cov --cov-report=xml
Notre CI calcule le taux de couverture sur chaque merge request et si le taux de couverture des fichiers modifiés par la merge request est inférieur à 90 %, elle affiche une belle pastille rouge indiquant qu'il manque des tests. Voici la commande qui permet de calculer la différence et de râler si on est en-dessous de 90 % sur les lignes modifiées par la MR en cours :
diff-cover coverage.xml --fail-under=90 --compare-branch remotes/origin/develop
C'est très bien. J'aime avoir une bonne couverture de test. Cela me procure une tranquillité d'esprit très appréciable quand j'ajoute ou que je modifie du code. Je sais que je peux faire confiance à mes tests pour détecter des problèmes dans mon code au fur et à mesure que je l'écris.
Mais calculer la couverture de code, ça coûte du temps et de l'énergie. Je n'ai pas besoin de la calculer à chaque fois que je lance mes tests sur mon poste. Par défaut, je décide de garder le calcul du coverage uniquement sur la CI.
Cela me fait gagner une trentaine de secondes sur 5 minutes. Ça fait un joli pourcentage d'amélioration si on aime faire le calcul, mais ce n'est toujours pas vivable au quotidien.
C'est là qu'un ami va m'aiguiller vers la vraie optimisation qui va rendre toutes les autres beaucoup moins significatives.
Utiliser un autre hachoir à mot de passe
Oui j'aime bien dire « hachoir » pour parler d'un hasher en anglais.
Au fil de mes recherches, j'avais vu plusieurs fois des articles conseillant d'utiliser un autre passwordHasher, et j'avais négligé en disant « oh ça va, on n'est pas à ça près quand même ! »
Eh bien figurez-vous que si, on est à ça près. Un bon hachoir à mot de passe, c'est lent. C'est trèèèèès lent exprès pour assurer la sécurité, pour que ça soit pénible de tester plein de mots de passe sur un ou plusieurs comptes donnés.
Sauf que dans mon environnement de test, je crée plein d'utilisateurs fictifs et mon pytest leur donne à tous un mot de passe soigneusement haché avec le hachoir haute sécurité.
La première étape a été de supprimer ceci à la fin de la fabrique (factory) de comptes utilisateurs fictifs :
# On est dans une classe UserFactory(factory.django.DjangoModelFactory)
@factory.post_generation
def set_password(self, create, extracted, **kwargs):
self.set_password(USER_PASSWORD)
self.save()
Cela a eu pour effet immédiat de faire échouer 2 tests sur 369, c'est peu ! Et surtout, de me faire gagner d'un coup la bagatelle de 4 minutes environ, puisque la suite de test entière s'exécute maintenant en 45 secondes. Je peux bien réparer deux tests si je gagne 4 minutes à chaque exécution de la suite.
Mais allons plus loin : ces deux tests, ce sont ceux qui vérifient que l'on peut effectivement se connecter en remplissant le formulaire de login. Donc pour ceux-là, j'ai besoin d'un utilisateur avec un vrai mot de passe, et ces tests-ci se révèlent particulièrement lents.
C'est là que l'on va décider d'utiliser un autre hachoir : le module pytest-django permet justement de surcharger certains paramètres, à l'aide de la fixture particulière intitulée settings . Et le paramètre qui décide quel hachoir on utilise, c'est PASSWORD_HASHERS : remplaçons-le par un tableau contenant uniquement la référence à MD5PasswordHasher.
@pytest.fixture(autouse=True)
def use_fast_password_hasher(settings):
settings.PASSWORD_HASHERS = [
"django.contrib.auth.hashers.MD5PasswordHasher",
]
Note : en dehors de l'environnement de test, ne modifiez pas ce paramètre pour remplacer le hachoir sécurisé par le hachoir MD5. Vous vous feriez allumer par n'importe qui de vaguement compétent en sécurité, et ce serait mérité.
Mais là ce n'est pas la prod, c'est l'environnement de test automatisé.
Avec cela, je gagne seulement quelques secondes : en effet, je n'appelais le hachoir haute sécurité plus que deux fois.
Point d'étape
Là où j'en suis arrivée, exécuter ma suite de tests complète dure une quarantaine de secondes. Je regarde à nouveau la répartition des tests les plus lents à l'aide de l'option --durations=10 : maintenant, je n'ai plus que des appels lents.
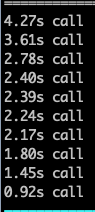
Croyez-moi sur parole si je vous dis que ces tests mous du genou correspondent à des vérifications intensives (plusieurs dizaines de clics et de requêtes http) sur des pages de l'appli qui sont elles-mêmes un peu longues à la détente.
La « bonne » démarche aurait été de se pencher sur la lenteur de ces pages ou de rendre les tests plus élégants que « cliquer partout et vérifier que tout va bien ».
Dans la vraie vie, j'avoue tout : pour gagner 30 secondes, j'ai désactivé ces tests en disant « ils ne servent plus à rien », et j'ai été détrompée moins d'une semaine plus tard quand nous avons subi une erreur 500 évitable en préprod.
Donc j'ai réactivé ces tests… Mais je les ai marqués "lents", pour pouvoir me permettre de les esquiver facilement si je veux gagner du temps.
@pytest.mark.slow(reason="On clique partout")
def test_mou_du_genou(client, les_url_a_tester):
for url in les_url_a_tester:
cliquer_partout_et_verifier_que_cest_pas_casse(client, url)
J'ai ajouté cette documentation dans le readme.md pour expliquer aux collègues — et à moi-même — comment éviter les tests lents :
# éviter les tests lents
pytest -m "not slow"
# n'exécuter que les tests lents (why not)
pytest -m "slow"
Paralléliser… ou pas… ou alors juste un peu
Le plugin pytest-xdist fournit la possibilité de diviser le travail de test entre plusieurs workers pour accélérer les choses. Pour cela, il suffit de lancer la commande pytest -n x où x est le nombre de workers entre lesquels diviser le travail.
On peut écrire -n auto pour créer autant de workers que l'ordinateur possède de cœurs (CPU). D'après la documentation, il s'agit des cœurs physiques (4 sur mon ordi) mais j'ai constaté que je me retrouvais avec le double (8, donc).
Quand j'ai râlé sur la lenteur d'exécution de mes tests, une des premières réponses de mes collègues a été : « utilise -n auto pour aller plus vite ! »
J'ai essayé mais j'ai constaté que c'était beaucoup plus lent, et leur réaction a été prévisible : le déni le plus total.
J'ai donc mesuré le temps d'exécution de ma suite de tests, en fonction de la valeur de n, de 1 à 8 (qui était le maximum sur ma machine). Pour cela j'ai utilisé l'outil hyperfine et j'ai veillé, c'est important, à ce que l'ordinateur ne fasse rien en parallèle.
(J'avoue tout : comme ce n'est pas vraiment palpitant à regarder, j'ai lancé hyperfine la nuit et j'ai regardé les résultats le lendemain.)
Voici la commande que j'ai lancée :
hyperfine --warmup 2 -i --parameter-scan proc 1 8 'python -m pytest -n {proc}'
L'option --warmup 2 indique à hyperfine de lancer deux runs d'« échauffement » car les premiers runs sont souvent un peu plus lents. Ensuite les options --parameter-scan permettent de paramétriser le(s) paramètres à comparer.
Je vous épargne le résultat textuel de hyperfine (je vous laisse essayer dans votre propre terminal) pour vous montrer le graphe du temps d'exécution en fonction du nombre de workers sur lequel on décide de diviser les tests (ici sur une suite de 650 tests) :
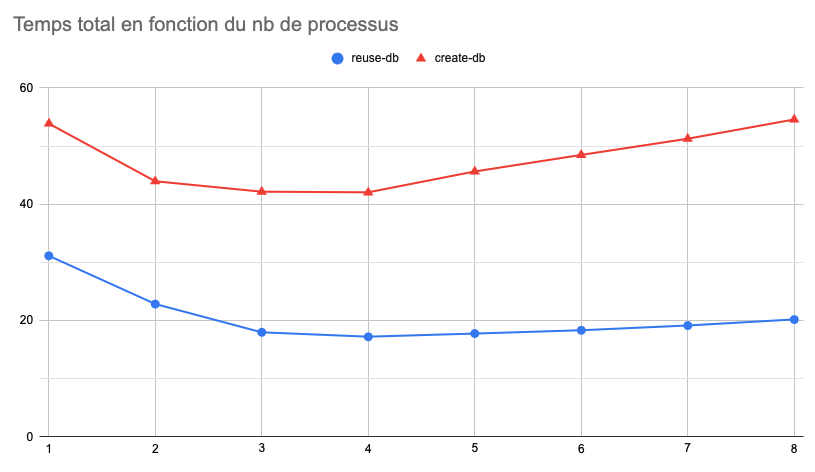
Que l'on décide ou non de recréer la base, on constate que le temps d'exécution total augmente dès que l'on dépasse le nombre de cœurs physiques de la machine (ici 4, sur notre CI c'est 12). Nous n'avons pas l'explication de ce phénomène, seulement des hypothèses.
La « bonne valeur » serait 4 mais en réalité, j'aime bien pouvoir continuer d'utiliser mon ordinateur pendant que les tests tournent : je passe généralement la valeur de n à 2 ou 3 selon le nombre de tests à exécuter.
En conclusion
Une fois n'est pas coutume, râler m'a servi à progresser et à gagner du temps, particulièrement ici sur mon poste de développement. Mon collègue Arthur a continué l'analyse sur l'exécution des tests sur la plateforme de CI, où nous avons gagné encore plus de temps ! Mais c'est un sujet pour un autre article.